seems btcd is way slower than bitcoin core in syncing? #1339
Comments
|
@lzl124631x there are couple reasons that btcd is slower than bitcoind. The main reason I see is that btcd download from one peer only in bootstrapping the blocks, while bitcoind download from 8. |
|
dcrd has an issue open related to multipeer downloads decred/dcrd#1145 which appears to be partially done. I haven't been following it closely enough to know if it is likely to be backportable to btcd but might be interesting to take a look at. |
|
@lzl124631x : If your node is in US (like mine), your connection will be slow to the default nodes in btcd DNSSeed under chaincfg/params.go . If you just manually add couple nodes in US, the bootstrapping speed will be much faster. For example add this to your startup btcd command:--connection=157.131.198.183:8333 --connection==209.108.206.229:8333 . The IPs keep changing, you can use the leaderboard to find latest IPs close to your country. I put more details in this post, if you want to look. |
|
@totaloutput Good to know that! But is bitcoind smart enough to sync with nodes geographical closer? If yes, why doesn't btcd have that yet? |
|
@lzl124631x I don't think current bitcoind code is smart enough to find geographically closer nodes to sync. (I could be wrong) The current code is to find 1 node to get the headers of all the blocks, and find 8 nodes to ask for the content (data) of the blocks, if any of the node is slow/unresponse for 2 seconds, it will drop that node and ask for a new one. |
|
I am using the btcd codebase to update the parallelcoin network (it almost even still has malleability vulnerabilities) and looked at the p2p syncmanager stuff. I made a small alteration that favours selecting the lowest ping out of the connected peers, the code is here: https://github.com/btcsuite/btcd/blob/master/netsync/manager.go#L261 where you need to make the change and here: https://github.com/btcsuite/btcd/blob/master/netsync/manager.go#L261 - I personally would think that more metadata stored about peers could get a more accurate picture of available block sources, such as a record of the last block/second rate when the peer was synced from. Still, lowest ping of up to 8 currently connected nodes probably still helps. btcd as delivered in the git repo has a series of checkpoints. When checkpoints are set, it pre-fetches the block headers and compact filters (if available). This likely actually slows things down during initial sync. I'd suggest trying to disable the checkpoints, to eliminate this double-downloading. Checkpoints are mainly to stop miners filling mempools with new blocks forked from ancient blocks, which are extremely unlikely to ever exceed the cumulative work total of the current best block. With my work on a forked chain, I am finding that when I set checkpoints, everything after gets orphaned. I am looking into this. Since checkpoints main purpose, in effect, is simply to reduce time-wasting old forks from clogging up the mempools, it's my opinion that the more effective strategy would be to simply disallow forks that would require an inordinate amount of hashpower to push ahead of the tip. Someone mentioned this a long time ago in a btctalk post, the idea of simply disallowing new blocks to attach before some reasonable number of blocks previously. I think it should be on the basis of cumulative weight. A reasonable figure could be derived from the known hashpower for an algorithm as currently exists on all networks. And yes, the btcd netsync library only downloads from one source at a time. I think it would make sense to improve this when it is syncing pre-checkpoint to establish several links and download several segments of the chain from several sources at once, while grabbing the blocks-only from a few nodes at the same time. The consensus chain could then be established earlier in the sync process and of course nonconforming blocks, the node serving them up should get a huge banscore increment for this, i mean, weeks of no contact, trying to propagate a fake chain is pretty serious. |
|
This is a huge bug. I am already waiting a week for BTCD to get all the blockchain. And this should |
I set connect=127.0.0.1, but it took three days to sync to 333365, and it's getting slower and slower. |
|
I'm getting about 1 block every 2 seconds. I tried modifying same It was much faster than this for the first 100,00 or 200,000 blocks. Slowed down in the mid-high 200.000's ... |
|
@justinmoon Same to me. At first, 200 or 300 blocks every 10 seconds; after 178411, less than 100 blocks every 10 seconds; now, somtimes 1 block every 10 seconds. Kick-ass! |
What version are you running? I pulled roasbeef/btcd, installed latest, but ended up with 0.9.0-beta, which had a lot of stalled sync problems, was processing 1 block every 2 minutes at mid 300k. Trying 0.12.0-beta now, I was doing 1k per 10s, but just passed 180k and I'm barely doing 200 per 10s now. |
|
@OlaStenberg I'm running master(version 0.12.0-beta). |
Ok, seem to be working a lot better for me with master, even if it slowed down to 20 blocks every 10s (around 350k). At what height did it slow down to 1 block every 10s for you? |
|
@OlaStenberg I started syncing from the begining again. At first, 17k blocks per 10s, now(204518) about 40 per 10s. And I find it's "fetchUtxosMain" that's so slow. Maybe there are some design flaws. |
|
Btcd sync time is around 10x slower than bitcoin core 0.18 for now. I did short profiling of the code in sync state and found that the incredible amount of CPU time is wasting by the garbage collector. This is in turn the result of the LevelDB calls. In the same time Btcd is using very low amount of the memory. In nowadays even a small devices like Raspberry PI has enough amount of the memory. I thing the right way of optimization is to improve the algorithm of LevelDB handling and to optimize malloc usage |
|
For me it was dealbraker and I switched to bitcoin core :( I synced whole blockchain in little more than day. With |
|
Two things stand out relating to this from my close work with the code on an old bitcoin fork (parallelcoin). One is the EC library. First thing I see is that the precompute could optionally be made a lot bigger, to improve performance, and on the other hand, also, using the fastest possible C library for koblitz curves optionally. Secondly I don't think that all of the problem with the database is the leveldb back end, though there is probably issues there (again maybe cgo option?) and in between that and implementing the interface, common code exists also. This issue is common for Go. I watched a talk a few weeks ago about a video streaming service where they found they basically had to single thread the scheduling of the streams to reduce blocking, which of course points straight at the GC being incorrect for the task. It shouldn't be mysterious because the scheduler's main workload overall is IO bound and that's a bad fit for CPU bound stuff like transaction validation and database cache management. Solving the problem probably will follow a pattern similar to the solution used by the streaming service, to explicitly schedule processing instead of trusting the scheduler, and minimising post init memory allocation with one big early allocation. All of which are a lot of work. The GC percent is default set to 10% and this is quite generous but still puts a ceiling on throughput, which conflicts with latency, in almost all cases. |
|
In my profiling, garbage collection and Here's what I have for allocations when syncing 2012 blocks: For And So these combined account for about 70% of allocations, but account for less than 10% of in-use space at runtime. In both cases, keeping some state so we reduce the number of allocations (and deallocations) would be beneficial. I bet replacing the immutable treaps in the dbcache would really help sync speed. LevelDB calls are also fine, they are all fairly lightweight - IMO the issue is the cache. More profiling probably needs to be done, but my guess is the dbcache. |
|
I'm trying to set up my own node with btcd instead of bitcoin core, since I want to support a healthy blockchain ecosystem. But after two weeks trying to sync the mainnet blockchain, it's just way too slow. I can't recommend anyone use this software when it takes so long just to get started. Sync times are increasingly slow as the block height rises - see the attached image.
(The gap on nov. 11 - 13 was from when I stopped syncing to mess with configs) |

|
I will be focusing on solving this problem in my project (github.com/p9c/pod), but thanks to Rjected I also have looked at some of the treap code as well as the script engine and I am pretty sure both have got serious garbage accumulation problems. Optimising them and aiming for zero runtime allocation will probably go a long way towards a solution. Incidentally, a part of btcd that I have had INTENSE work with is the CPU miner. It uses two mutexes, and stops and creates new goroutines constantly. I built a library that allows me to attach an RPC to the standard output, built a small, dedicated single thread (two threads but primary work), I use two channels, stop and start, and I thought I would need an atomic or compareandswap but it turns out just using two channels and a for loop with a 'work mode' second loop, both parts of the loop drain the channels not relevant (the runner ignores the run signal channel and the pauser ignores the pause signal channel), and the lock contention is obviously so bad that a little over 10% of potential performance is chewed up with synchronisation. I know well enough from what I saw of the script engine and database drivers/indexers that the programmers who write it are obviously former C++/Java programmers because they pretty much mainly rely on mutexes for synchronisation and mutexes, which are the slowest sync primitives, and where channels are used, in places that I would expect to see async calls used in these older, less network-focused languages. For bitcoin forks, especially small, neglected ones like parallelcoin, its sync rate is fine. 8 minutes on my Ryzen 5 1600/SSD/32gb machine, at a height of about 210,000. The chain barely has maybe 2 transactions per block, on average. But even still, at 99000 and again around 160000 it bogs down badly and appears to be mainly garbage collecting, so with the typical block payload of bitcoin, I imagine the complexity of the chain of provenance of tokens explodes exponentially, and that graph exactly shows this pattern. I'm not sure where I will start with it, but I strongly suspect write amplification is also hiding in there, a performance problem well known to be existing with LevelDB, and even RocksDB and BoltDB, and resolved in Badger, so first step will be building a badger driver. I'd guess that especially as the number of transactions grows that write amplification is causing an issue every time the database updates the values it has to write the keys again as well, combined with the geometric rise in complexity of validations to confirm they correctly chain back to the coinbase. Second thing I expect to look at is the treaps. There is some parts of btcd that attempt to eliminate runtime allocations, at least one buffer freelist, but there is a lot of creation of small byte slices that are discarded later. As tends to be the case with Go, the naive (I did mention the mutexes, they are a naive use of Go) implementation does not take into account GC or thread scheduling, and when the bottlenecks are really bad, usually it means you have to take over both memory and scheduling work from the Go runtime to get a better result. I already saw one clear example of this just in the use of isolated processes connected via IPC pipes and using two channels and one ticker instead of 2 or 3 mutexes and 3 different tickers made it produce more than 10% more hashes. If anyone is interested who is following, keep an eye on the repo I mentioned above as over the next 6 months I will be focusing on optimizing everything. I am nearly finished implementing the beta spec for my fork, and I have aimed to make it accessible enough and not stomping over top of too much of what is already there that differs for the chain I am working on. I am still a bit lost as to how to enable full segwit support, and you will see I have merged btcwallet, btcd, btcutil and btcjson repositories into one, created a unified configuration system, and mostly done and robust handling of concurrent running of wallet and node together for a more conventional integral node/wallet mode of operation. I understand some of the reasons behind so vigorously separating them but in my opinion in the absence of a really good SPV implementation makes doing this a step backwards. Based on watching CPU utilization and a little bit of profiling I can see so much empty spaces between with CPU doing literally nothing for about 60-70% of the time, during the sync process, so I am very leaning towards the idea that synchronization is the bigger issue, and second is garbage generation, and thirdly, write amplification due to the database log structure, with updating metadata related to block nodes in the database. |
|
By the way, out of curiosity I tried disabling the addrindex and txindex while on initial sync. Not only did it not seem to take any less time, the amount of metadata generated in the database folder looked exactly the same as though it was on. I am not sure if it is ignoring my configuration change, I checked through all the places where that setting is read and it definitely should not have been running the indexers. |
|
Looks like a memory ballast could be in order... |
|
I remember reading this one before. I am going to try it out with my fork at https://github.com/p9c/pod and I will report back if it gets that kind of result (it is on a different, much smaller change but even still appears to have at least one big GC cleanup every 50-100,000 blocks and that is at least part of the problem for sure, as one or two blocks end up taking like a minute to process. |
|
Hey @l0k18, what ended up happening? If it worked I'd be happy to port here since this has become a much bigger issue |
|
So the ballast (10gb) does appear to substantially increase the garbage collection rate: It looks like the greatest decrease here comes from: This appears to result in a 3x increase in heap size: |





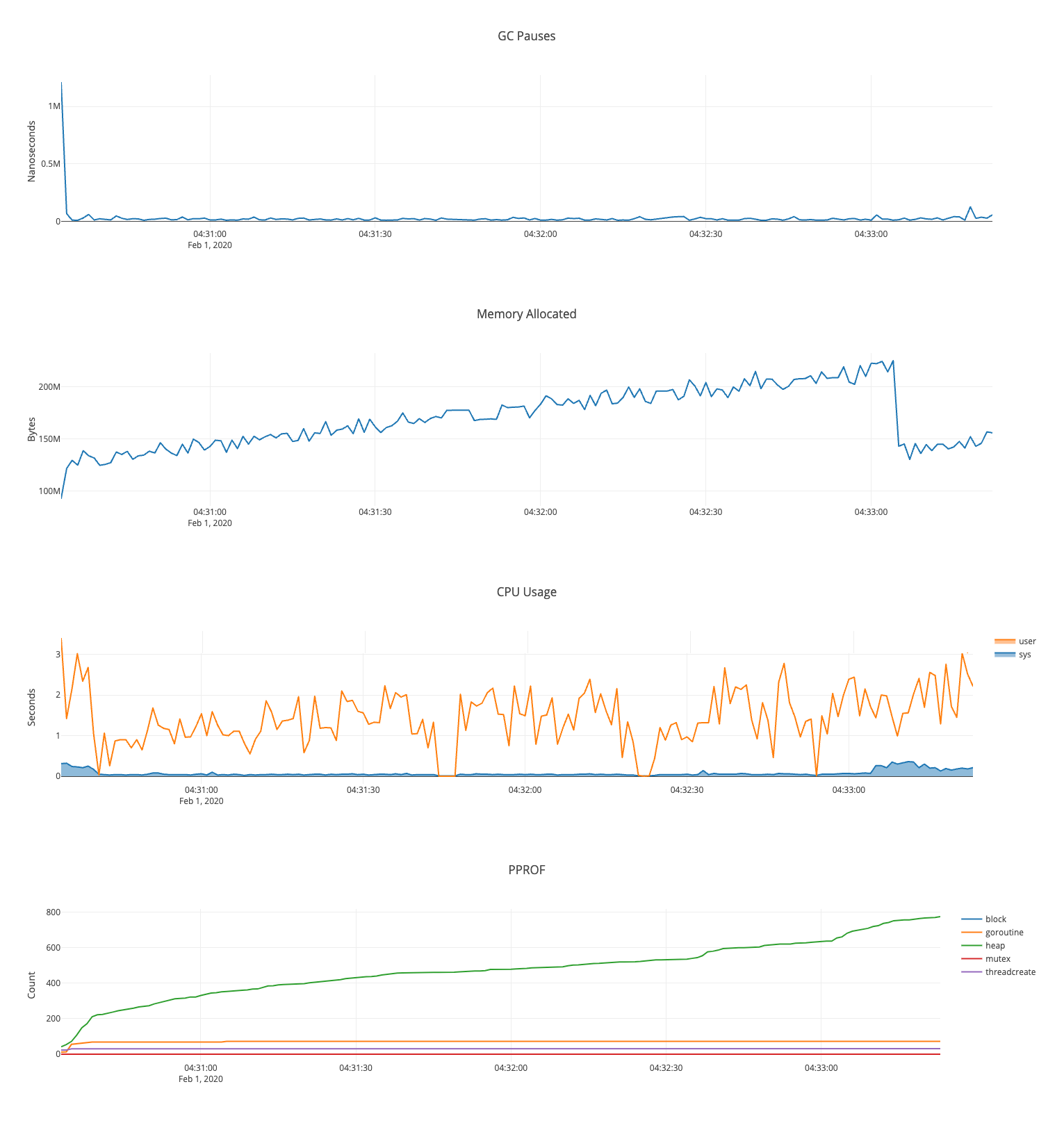


|
I'll need to do a full sync to confirm, but it looks like a 3x increase in memory can get us a 3-4x increase in block sync speed. Ballast does not appear to improve allocation speed |
|
I have been working on a fork coin using this engine and I found it maxed out about 2000tx/s syncing from a node on my lan. I suspect this may be structural limit caused by signature verification performance. It has been a couple months since i was working on it so my memory might be hazy but i think it got best performance with gc limit at 100% which i think is 'no limit'. I hadn't tried the ballast, and in a couple of days i can confirm. |
|
Yeah, that's what I'm thinking. I think this is going to come down to a memory/cpu trade off. Maybe we can add a config option in here |
|
Has there been any update on this problem? With the txindex and addrindex set to on, I'm syncing 1 block every minute! At this rate it will take over a month to sync. This makes the software completely unusable. If the problem isn't being worked on, is there any other stable libraries that offer the the txindex and addrindex options? |
|
@Colman I've never seen it that slow. This sounds like it might be a disk i/o issue. Are you using some kind of NAS? Alternatively - there are a few high impact PR's that would go a long way toward speeding this up. The most notable is probably #1373. It'll depend on your disk i /o but as @Roasbeef point's out that PR gets sync >24 hours. Would be great if you could help get that merged. As far as other servers, it looks like you could check out this fork bitcoin/bitcoin#14053 |
|
Well I'm using Amazon's EBS which I think is considered NAS. I've tried their regular SSD and their high performance one which both yielded the same result. As far as I know, the latency between the machine and the EBS is <10ms, which IIRC, is the bottleneck right? Either way, why does the hard drive affect it that much? As far as I know, you're only accessing it to modify the UTXO set, TX index, and address index which can be done in batches. Also, I checked out the @Roasbeef fork and even if a UTXO cache was implemented, I still don't get why it's so slow without one. |
|
In my experience - it has a pretty big affect. We've got like 6 btcd nodes running in gcp and we had to switch them all over from I don't remember the exact numbers but bitcoind has a similiar step function with the sync times being much lower (but differing commensurately) across the board |
|
Okay I looked in to the specs for the AWS disk that I'm using and it's quite similar to yours. However, mine has been syncing for a month and still isn't done so obviously something else is up. What's your CPU and RAM specs? And are the timelines you gave me measured with the txindex and addrindex settings set to on? I'd assume they would increase the sync time. |
|
@Colman If you are using a general-purpose EBS volume ( gp2) you can only get 1500 IOPS and 250 Mbps baseline speed for the volume of 500Gb, and lower for a smaller volume. This is far below any SSD disc, so the disk IO may be a root cause of slow work in this case. You may try to use provisioned IOPS mode which is more expensive but closer to SSD performance. |
|
Okay good to know thanks. I tend to avoid the IOPS ones because the last time I used it, I got charged like $120 just for the month which is totally outrageous. They probably pay off that drive in less than 2 months. |
|
Also, is there a way to make RPC calls while the blockchain is syncing? I would like to see if the tx index will be fast enough to use before I spend all this money on the drives to sync it. |
|
n1-cpu-4, but there is a fair bit of variance here in our llvm setup. I actually wrote a custom provisioner to combine the local disks into a single logical volume and iops increases with the number of disks
|

|
This problem still exists in 2021! It is taking more than one day for me sync the blocks for 2017 |
|
I want to confirm that my memory-pressure measurements today show that the |
|
To anyone having performance issues when syncing you could try to set: (if you have enough memory that is) It seems to have dropped from 1 block per 60-90 seconds down to 10-20 seconds for 1-3 block's, with a few hiccups here and there..... Unless there was some huge drop in block-complexity around this height. Summary of the behavior i can see on my system and some "gut-feeling" around a possible culprit that we might want to investigate, but too unfamiliar with the btcd codebase to do anything myself.. I'm doing a import on a 4 core 3.2Ghz with 32Gb RAM and 4x4TB HDD's running in raid10. Funny thing is that i started a bitcoind sync, to the same filesystem, and it fully synced in 2 days while btcd is still at mid 2018 after over a week. ;) One thing i have been thinking about is the lack of O_DIRECT fs access in go... Usually databases bypass the buffercache for writes (at least) to databases to reduce the memory fragmentation of pending writes.. Not sure if that's related to the issue here since my Dirty blocks usually stays around 10-15MB in /proc/meminfo) Currently the only application that is doing io against these disks btcd, with a few read-spikes of bitcoind from every 30-60 seconds or so.. IO usage by btcd, as reported by iotop, stays between 85-100% with ~500KB/s read and ~4-6MB/s writes and IOP's for the raid10 jumps around between 70-140 tps. in iostat. CPU usage of btcd jumps up and down all the time, but never breaks 100% so go routines does not seem to be used that much? If wanted i can make a copy of the blockchain and run any tests you might want at this height... Just give me a shout... |
|
@pakar I think it would be great if you uploaded a snapshot of the btcd chain for posterity, especially if this situation is not going to improve anytime soon. |
|
@strusty Only been syncing during idle-time on the system so not yet fully synced. Create a new issue and reference me in it if i should do something. |
|
@pakar I will set this up, and await the good word from you when you have it all synced. I will let you know here once it is ready. |
|
Ok, same issue here, btcd is ridiculous slow. This seems to be mostly goleveldb related (as others have stated). The following PR seems highly relevant: syndtr/goleveldb#338 bitcoind configures leveldb based on a memory flag. I am using I am also using That said the initial sync is still days off but at least it is making decent progress. |
|
Another idea: I ran It's not a solution of course but a mere workaround. A real solution is to stop producing so much garbage during IBD but I understand it might be harder than it sounds. |
An easy first step then would be to add a parameter to the configuration to set the GOGC value and enable users to activate a high value for initial sync. This is a quite trivial PR. If nobody else wants to take it and it is acceptable to the dev team I'll put this together. |
|
#1899 I have created a PR that adds GOGC and GOMAXPROCS configuration to the configuration system. This change can almost double the speed of initial sync and improves the rate at which the DB is updated to new blocks, which is important for miners. |
|
Hi, I'm doing DB indexing (all blocks are retrieved yet) on a VPS hosting and it is going VERY slow, I'm running it for 3 months yet and still 2 years of blockchain left to be processed. I suspect main reason is HDD IOPS limit on VPS hosting. RAM is 20G there. I see that there are around 100k of small files *.ldb in ~/.btcd/data/mainnet/blocks_ffldb/metadata/ - is it DB index? Also will be good to have trusted precomputed DB hosted somewhere to sync from. And just hash checking then is needed to check that it is original and not tampered. |
|
Badger and Rocks are designed for SSD, Badger's main difference is using a pair of logs for key and value. Pogreb would probably be a really good back-end for chain data due to its design optimization for infrequent writes and frequent reads, but during IBD it's gonna be heavy writing. It's basically impossible to use
The indexes consume around 150-200gb extra space, or about 25-33% of the total data amount and generating them requires a lot of random access. On the other hand, if you were to upload a Even a KVM or similar type VPS with SSD will still have a substantial iops limit, but you won't also have the slow and highly variable seek latency of a spinning disk. If your plans include using chain data and you can't upgrade to a VPS with a faster disk, you might want to consider maybe running a full node at home, creating an SSH tunnel to the VPS, and run Neutrino on it, if your intention is to run If you are a little experienced with writing Go server software, it is actually not hard to create a launcher that spins up Neutrino as a stand-alone server, possibly someone has already done this, and it is not difficult, as Neutrino is written to be able to run as a thread in another application (LND is also, but not quite so easy to work with). Indeed if the idea is to have a website with access to chain data, you can shoehorn it into your existing Go based web application. Possibly https://mempool.space already has this configuration option in its codebase. The caveat is you need to give Neutrino access to a btcd or bitcoin core instance with BIP 157 (neutrino mode) enabled for the cfilters. Thus the suggestion you could make this connection from a home server for this, also, if you have ever used Zap wallet you would know that there are publicly accessible full nodes with neutrino mode enabled set up by Zap's developers zaphq.io, there may be others. Regarding your last point, it is simple enough to do the initial sync this way, and for which reason I personally pause my |
Yeah, I did it this way. I already downloaded all blocks without indexing, it took more than month, and now it is doing just indexing and it is lasting 3 months yet and counting. Thanks for other suggestions I will look into it. |
Your question prompted me to try testing out running a btcd instance off my 2.5" backup drive, and the results so far look like for 5400RPM HDDs at least, each block as it's syncing is taking between about 2 and 13 minutes to simply validate the block. It is probably not as bad for a 7k RPM or even 10k RPM disk but I think the time is coming where it's simply not possible to use a standard HDD to run a node because it can't keep up with realtime block discovery speed. Previous to this I had also used I think that for sure |
|
The index speed right now from 30 sec to 5 min per block. But I suspect that it is hitting IOPS limits set in hypervisor for VPS instance as sometimes it is working 20-40 sec per block, sometimes it is 1-3+ min for long period of time. Maybe I will fiddle with fs tuning to enable write-back in-memory file cache, but it can end up with corrupted data in case of shutdown. |
|
Actually the problem seems still to persist. As In China I Still all this is frustrating slow and hard to grasp that 2023 this is still an issue. Unfortunately the workaround suggested by @Roasbeef does not work. If yopu try to compile So I was really really thanksful for
|
Sure. |
I remember I used bitcoin core to sync btc full node on EC2 (200+G) in one day. But I used
btcdto sync full node -- two days later it just synced 108G ?The EC2 config is the same.
The text was updated successfully, but these errors were encountered: